NativMMQA
Framework, datasets, and benchmarks for culturally aligned multilingual and multimodal QA
Framework + datasets + benchmarks
Build and evaluate culturally grounded QA resources across languages and modalities.
NativMMQA brings together the NativQA Framework and public benchmark resources for culturally aligned evaluation. Our work currently spans MultiNativQA for multilingual natural QA and EverydayMMQA/OASIS for culturally grounded spoken visual QA, giving one entry point for building, benchmarking, and extending datasets for LLM evaluation and fine-tuning.
Explore the ecosystem
Framework
NativQA Framework
Use the framework to create culturally and regionally aligned QA datasets for multilingual and multimodal model evaluation and tuning.
Dataset
MultiNativQA
See links, live download metrics, language coverage, regional scope, and topic distribution for the multilingual natural QA benchmark.
Spoken visual QA
EverydayMMQA / OASIS
Explore the multilingual and multimodal framework for culturally grounded spoken visual QA, with paper context, dataset scale, and benchmark takeaways.
Why this work matters
Native-speaker grounded
Queries are sourced from native speakers and local contexts, making the data closer to real information needs than generic prompt collections.
Multilingual and multimodal
The site now covers both natural QA and spoken visual QA, making the resource collection broader than a single benchmark page.
Reusable across workflows
The same framework and resource family support benchmarking, analysis, and the creation of fine-tuning data for culturally aligned systems.
news
| Nov 13, 2025 | Fostering Native and Cultural Inclusivity in LLMs |
|---|---|
| Jan 23, 2025 | Multilingual and Multimodal Cultural Inclusivity in LLMs |
| Nov 13, 2024 | Fostering Native and Cultural Inclusivity in LLMs |
latest posts
| Jul 16, 2024 | Arabic Language Technologies – Medium |
|---|
publications
-
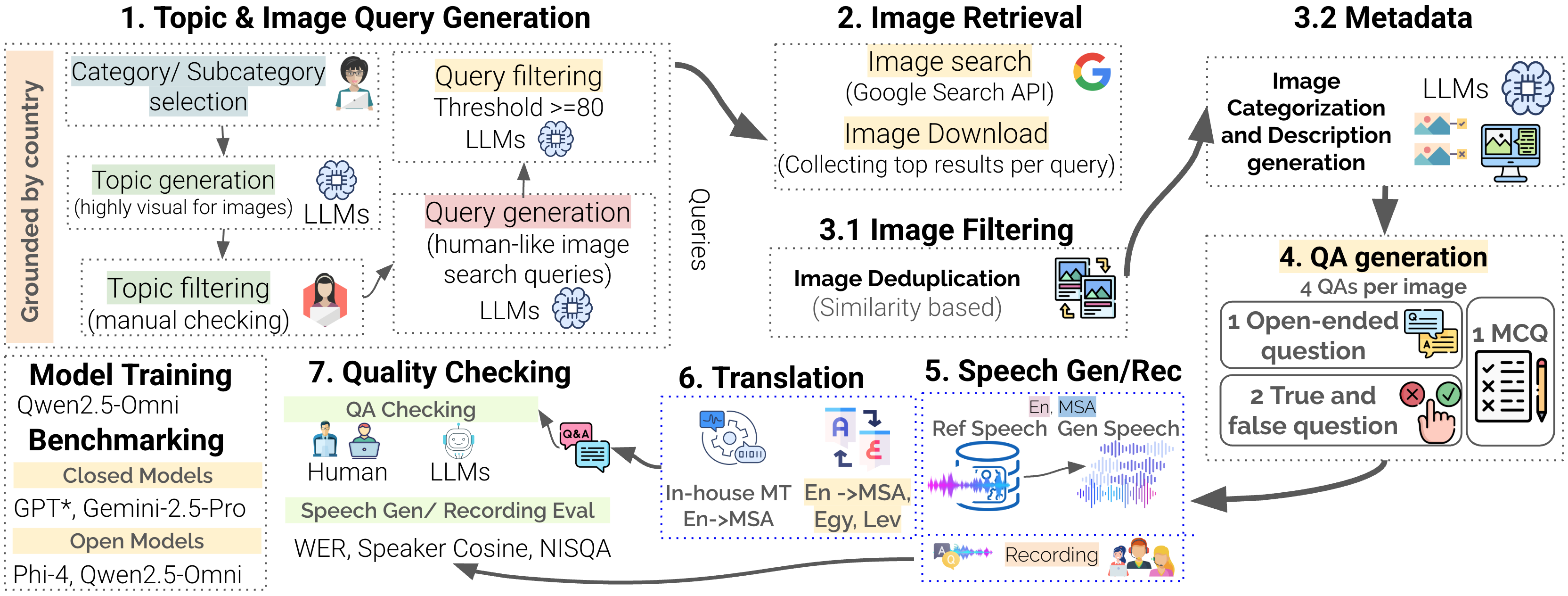 EverydayMMQA: A Multilingual and Multimodal Framework for Culturally Grounded Spoken Visual QAarXiv preprint arXiv:2510.06371, 2025
EverydayMMQA: A Multilingual and Multimodal Framework for Culturally Grounded Spoken Visual QAarXiv preprint arXiv:2510.06371, 2025 -
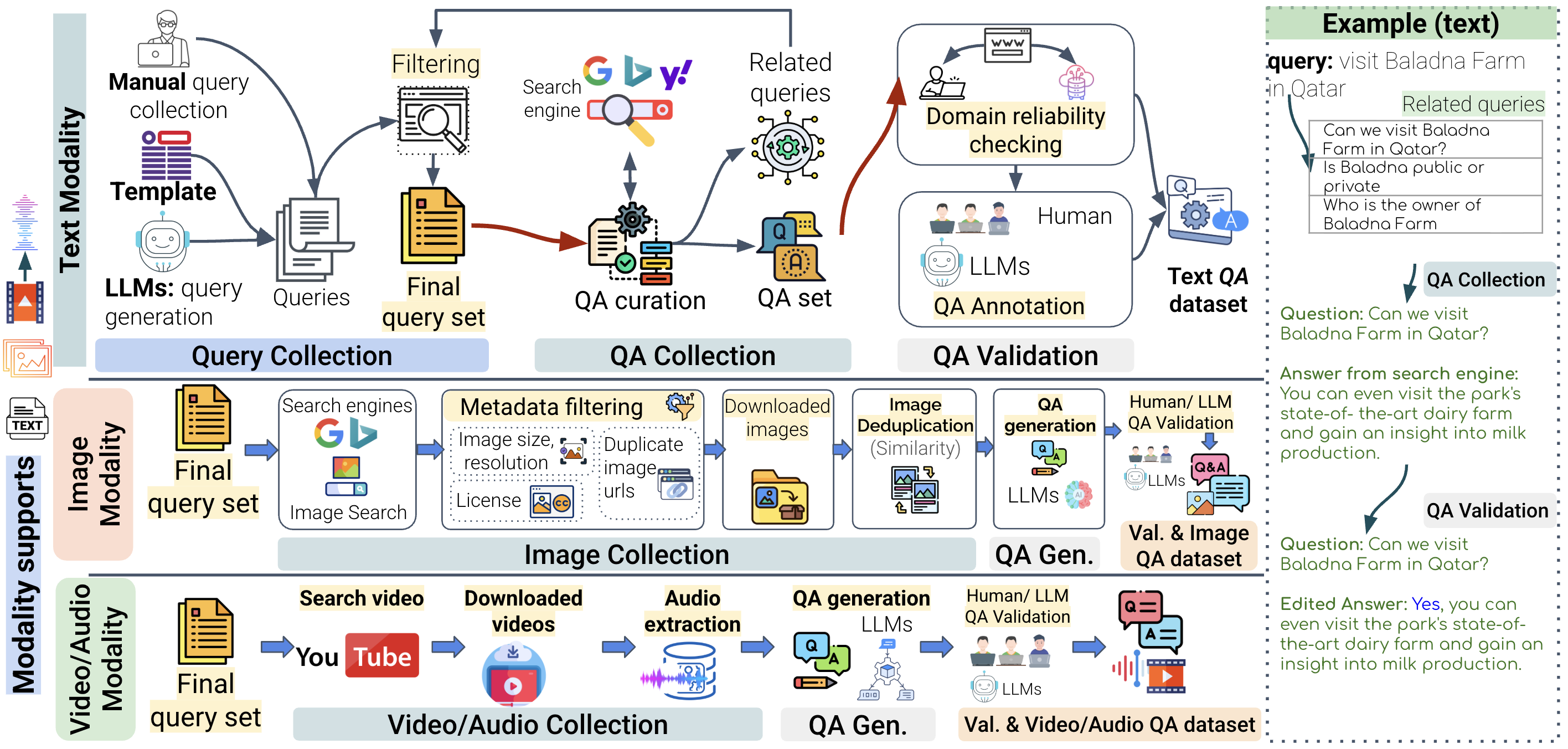 NativQA Framework: Enabling llms with native, local, and everyday knowledgearXiv preprint arXiv:2504.05995, 2025
NativQA Framework: Enabling llms with native, local, and everyday knowledgearXiv preprint arXiv:2504.05995, 2025 -
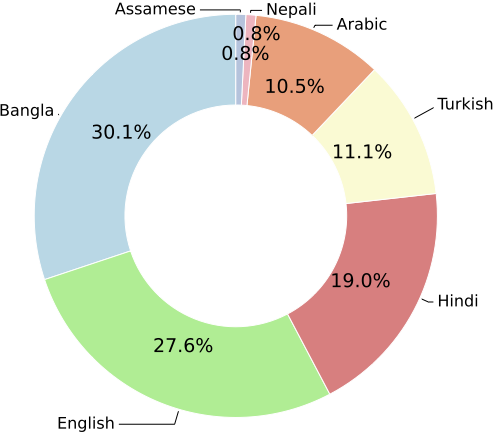 NativQA: Multilingual Culturally-Aligned Natural Query for LLMsIn Findings of the Association for Computational Linguistics ACL 2025 , Jul 2025
NativQA: Multilingual Culturally-Aligned Natural Query for LLMsIn Findings of the Association for Computational Linguistics ACL 2025 , Jul 2025 -
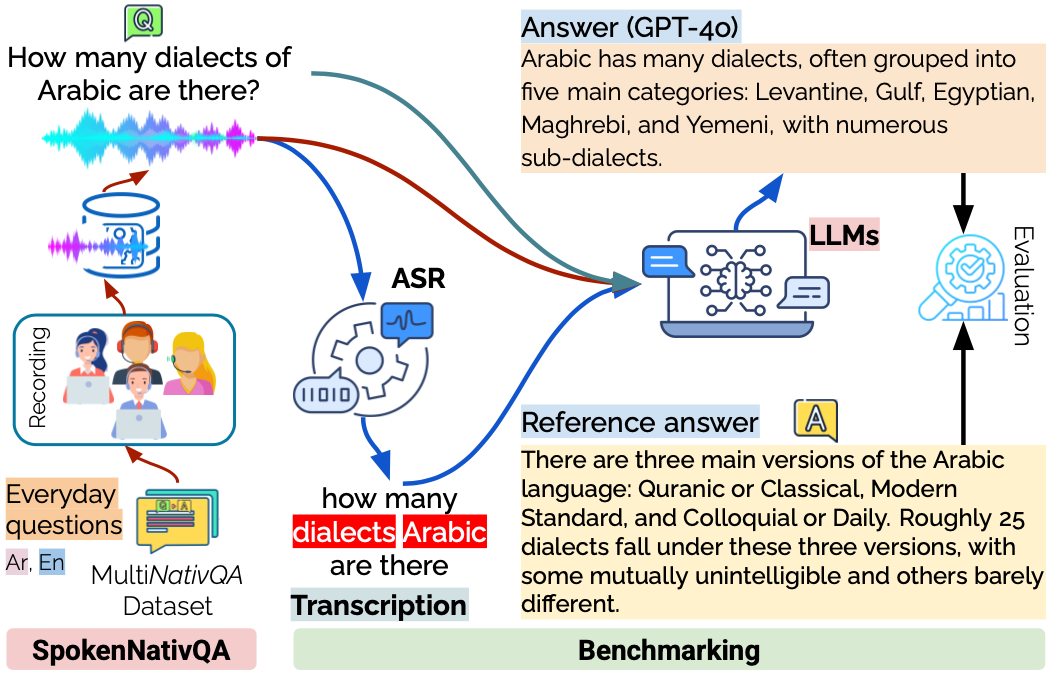 SpokenNativQA: Multilingual Everyday Spoken Queries for LLMsIn Proceedings of the 26th Interspeech Conference (Interspeech 2025) , Aug 2025
SpokenNativQA: Multilingual Everyday Spoken Queries for LLMsIn Proceedings of the 26th Interspeech Conference (Interspeech 2025) , Aug 2025



